My college thesis project, completed in August 2023. This post is intended to provide a quick summary of my thesis, you can read the full paper by following the link at the end of the page.
This paper looked to address predicting residential rental price in Dublin and the determinants of the prices. Machine learning models are commonly deployed in the property market and have been used for predicting both residential sales and rental prices. This study utilizes these models to provide a prediction for residential rental properties in Dublin City. The objective of this paper was to identify a single machine-learning model that could best address this need by accurately predicting rental prices while revealing important determinants of rental prices. These determinants can help to identify what itis about a property that drives rental price and whether these are property-specific characteristics, such as the number of bedrooms or location, or economic-based factors.
Real estate prediction models have already been established by current literature both globally and in the Irish market. However, this paper focused on creating a model specific to the Dublin residential rental market, something I did not come across in my research.
Ireland is currently in a housing crisis. Younger generations like myself are being forced to rent due to the increasing cost of purchasing property.
There is also not a lot of transparency in the current rental market. Some of the listings being published seem extortionate for what you get, so I wanted to find a solution that could predict the rental valuation of a property so that there is more information surrounding the market.
The data for this paper was scraped from Daft.ie using the daftlisings library created by Anthony Bloomer. Data was scraped in April, May & June 2023 daily using Python.
I had originally intended to investigate all of Ireland but when I had the data scraped and put together, over half the properties were located in Dublin. Also when I started looking at adding the additional variables, this data was only freely available in Dublin, which is why the paper focuses there.
The reason I chose to do multiple machine learning models is because in my course we did not go into detail on every method for machine learning due to time constraints, but instead focussed on some key methods. Whilst researching for my Literature Review I noticed that papers were referencing methods that I hadn't covered in class, and so the self-learning aspect of attempting these methods excited me about the project. Also a number of papers reviewed drew comparisons between models so this is why this approach was chosen.
The research question identified for the paper was:
Can rental prices in Dublin be estimated effectively using machine learning models?
This question would be achieved by completing the three objectives set out below:
1. Create a machine learning model that can predict the monthly rental price of a property utilizing property characteristics
2. Create a machine learning model that can predict the monthly rental price of a property utilizing both property characteristics and additional factors such as geographical, population and economic factors.
3. Assess whether the model which performed best in Objective 2 can be used to predict the results of a more recent month of new rental properties.
The original data was scraped from Daft.ie daily throughout the months of April, May & June 2023, however the June data was withheld from the process for the validation set.
The additional characteristics set adds various property characteristics to the original set such as the distance to the nearest park or the number of bus stops within a 5-minute walk. These added features aim to enhance the dataset and were obtained from several sources.

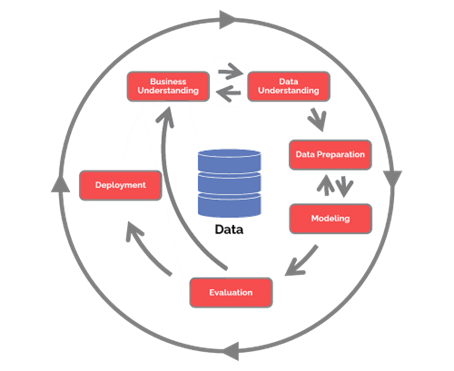
The Research philosophy chosen was positivism because this approach focuses on quantitative data and can be replicated in the future. The CRISP-DM Framework was chosen as the research design to plan the project work. Each stage of the paper is broken down under the headings of the framework. As you can see below, it is a cyclical approach but also affords the opportunity to go back through the stages where needed.
The seven machine learning models used in this paper were:
These models were chosen from the literature review, as they appeared in many of the papers I had looked at before commencing the project.
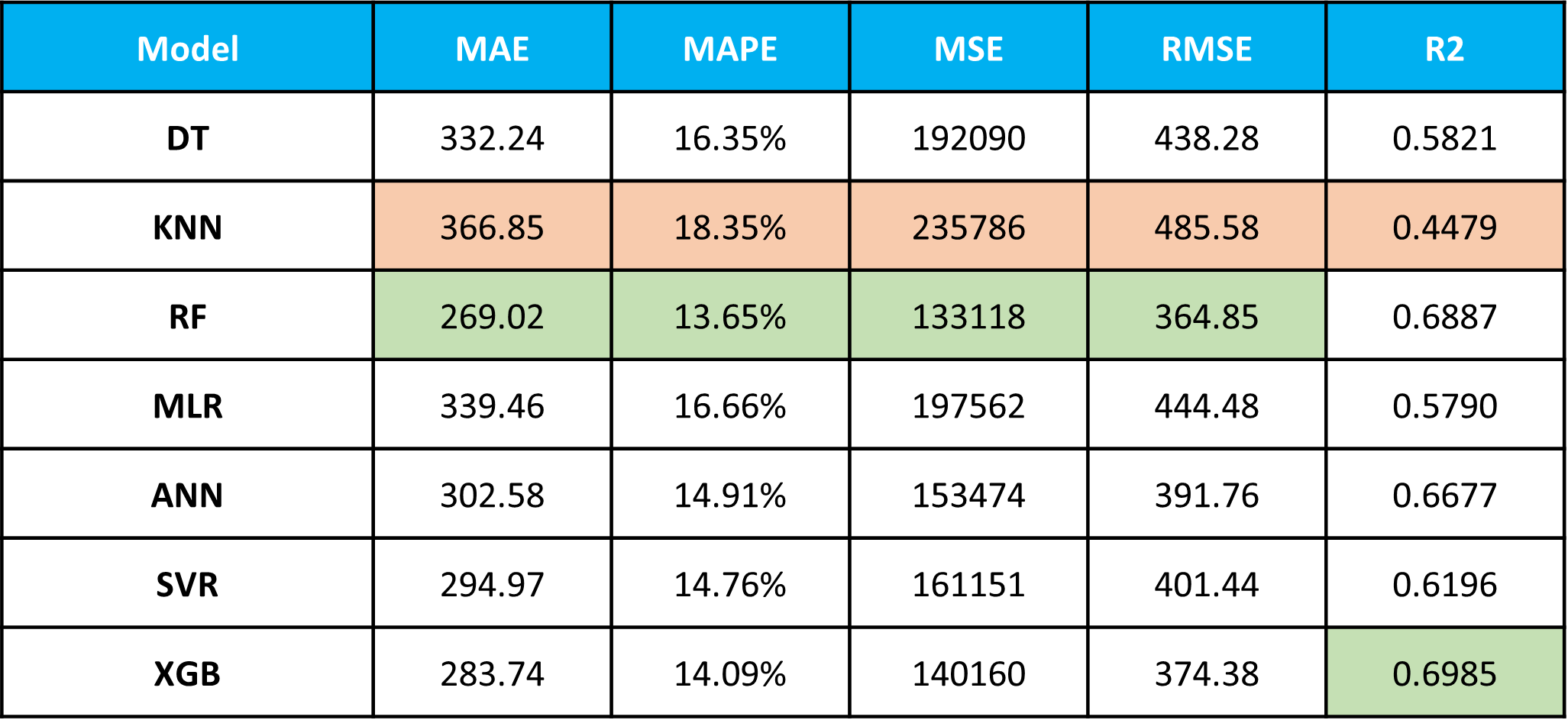
The table above shows the results of the machine learning models on the original characteristics dataset. As you can see the KNN model performed the worst. The Random Forest model performed best on these characteristics.

The table above shows the results on the additional characteristics dataset. As before, KNN performed the worst. Both Random Forest and Gradient Boosting models performed well. The gradient boosting model was chosen to be validated as it outperformed other models in 3 out of the 5 metrics.
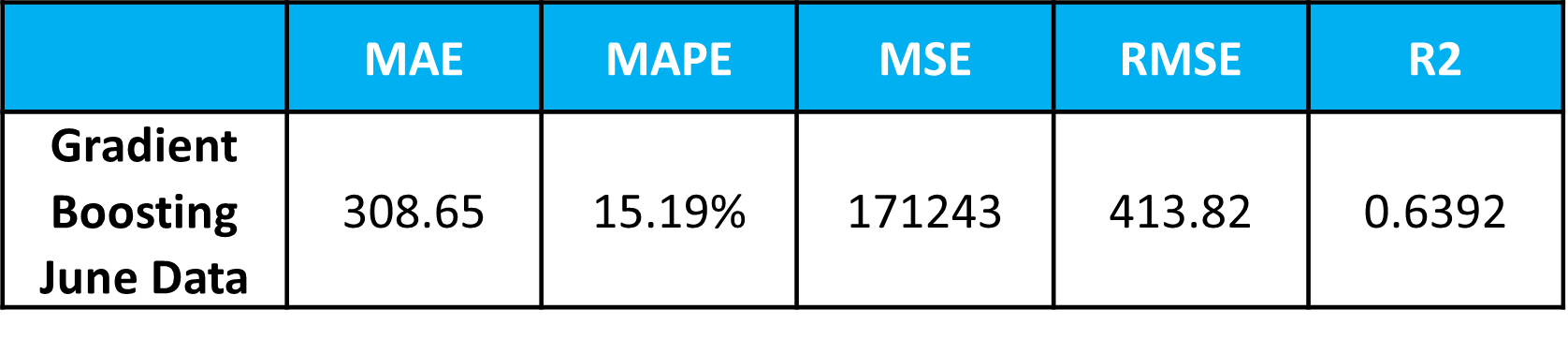
The results of this model are shown on the table above. The results mean that the model is capable of predicting rent prices to within €309 or to within 15.2% of the listed price, on average.

The graph above shows the predictions versus the true values for the first 25 properties in the dataset. Whilst it’s not hitting every point, the peaks and throughs are alike and the model certainly works better than just guessing the average price for a property.
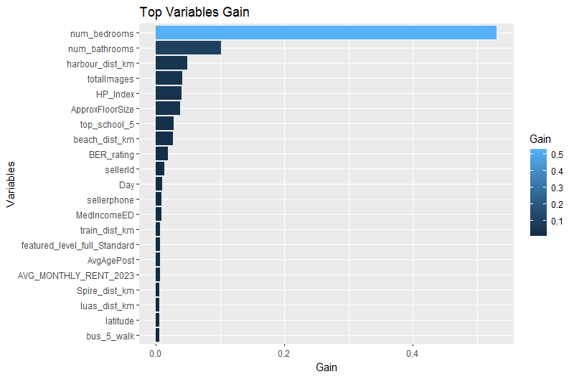
In terms of the variables that are important, the number of bedrooms, energy rating and distance variables such as proximity to harbor, beach or train station were found to be important to the model.
The initial objective of this paper was to develop and assess the machine learning models which used data from the property listings. In total seven different machine-learning methods were used and the creation of these models successfully achieved the first objective.
The second objective in this paper was to enhance the initial dataset with additional characteristics. This objective was achieved successfully through the creation of the models using the additional characteristics.
The third objective in this paper was to use the best performing model from Objective 2 and test it on unseen data gathered in June 2023. As I just showed, this model was capable of predicting rental prices on this data and therefore this objective was also successfully completed.
Overall, since each objective was successfully achieved, this has answered the identified research question.
R Studio was used for this project. Other software such as Python, Excel and Tableau were used infrequently through the analysis, cleaning and understanding of the data but R Studio was used for all modelling and evaluations.
CRISP-DM Methodology was chosen for this paper to provide a structured layout for the report. Each stage has been deployed throughout the paper, with the deployment stage utilized as a further reiteration of the best performing model.
I touched upon this in the paper but there have been some interesting studies that have used the imagery taken from property listings and assessed neighborhood affluence or whether the room photographed is luxury or not, and this is something that could really enhance this paper.
Also, this paper was always intended to be repeatable, in that it doesn’t serve much purpose if it can’t assess a rental property when you want it to and I think the paper achieves this.
In case you’d rather have a quick look at my review of the project I have put together the below video.
You can view the paper on my google drive here: https://drive.google.com/drive/folders/10UpkJvH6zmQTWy6TyfDSjCUtRkfrmKV9?usp=drive_link
